HabileData provides frame-by-frame and interpolated video annotation services for AI companies building object tracking, action recognition, event detection, and scene segmentation models. We annotate 50,000+ frames per day at standard throughput, handling MP4, AVI, MOV, and extracted frame sequences, with consistent cross-frame object identity, track ID assignment, and semantic class labeling. Our ISO-certified infrastructure and NDA-compliant workflows protect proprietary video data throughout the annotation process.
Get started with a free pilot »
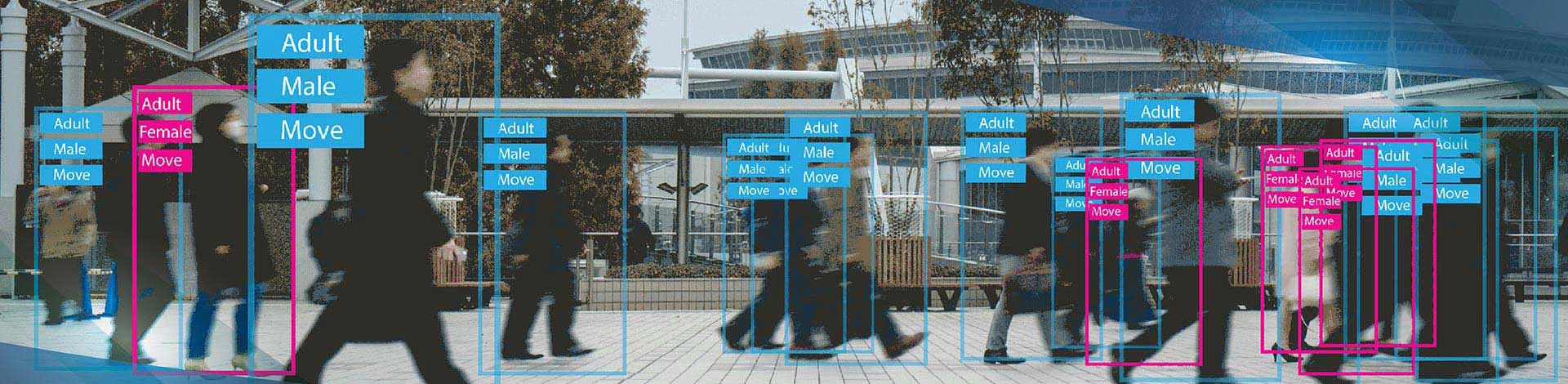
Video annotation services are essential for building accurate AI and machine learning models. Unlike image labeling, video data requires consistency across frames, where issues like ID mismatches, inconsistent labeling, or broken tracking can impact model performance.
At HabileData, a trusted video annotation company, we help businesses outsource video annotation services with confidence. Our process begins with customized annotation guidelines that define object tracking rules, occlusion handling, and clear action boundaries. We run pilot batches to measure inter-annotator agreement and only move to full-scale production once quality benchmarks are achieved, ensuring consistent and high-quality data labeling outcomes.
Frame-level consistency – where video annotation fails silently
Unlike image labeling, video data requires consistency across frames. ID mismatches, inconsistent labeling, and broken tracking compound across sequences and impact model performance. These errors often go unnoticed during basic quality checks, making a structured annotation approach critical from frame one.
Pilot-first process – production starts only after benchmarks are met
Our process begins with customized annotation guidelines that define object tracking rules, occlusion handling, and clear action boundaries. We run pilot batches to measure inter-annotator agreement and only move to full-scale production once quality benchmarks are achieved — ensuring consistent and high-quality labeling outcomes.
Full video labeling stack – from bounding box tracking to action recognition
Bounding box tracking, polygon and semantic segmentation, keypoint annotation, action recognition, and 3D cuboid labeling — delivered on CVAT, Labelbox, Scale AI, or your proprietary platform. We work within your existing tooling and adapt to your annotation schema, not the other way around.
Enterprise-grade security – sensitive video data stays protected
NDA coverage, encrypted data transfer, and controlled access environments are built into every video annotation project. Your sensitive video data remains protected while we deliver scalable, accurate, and reliable annotation solutions — security is part of the workflow, not a separate policy document.
We provide the following video annotation techniques, individually or in combination for complex multi-class video datasets:
Frame-level rectangular object labeling with persistent track ID assignment to maintain object identity across video sequences. Our approach ensures reliable multi-object tracking (MOT) datasets, compatible with frameworks such as SORT, DeepSORT, and ByteTrack for production-ready AI models.
High-precision vertex-based annotation for irregular and dynamic object shapes across video frames. This technique is critical for applications requiring exact boundary detection, including medical imaging workflows, agricultural drone analysis, and precision manufacturing inspection.
Pixel-level classification of every frame to enable comprehensive scene understanding. We maintain strict temporal consistency across sequences, supporting advanced use cases such as autonomous driving, geospatial mapping, and intelligent video analytics.
Accurate annotation of skeletal joints, facial landmarks, and structural reference points across video frames. Our expertise supports pose estimation, gesture recognition, sports performance analytics, physical rehabilitation AI, and workplace safety monitoring systems.
Temporal annotation of actions with clearly defined start and end frames, action classes, actor identification, and confidence scoring. This enables robust behavior modeling across surveillance systems, sports analytics platforms, and industrial process monitoring.
Three-dimensional object labeling capturing position, orientation, and volumetric attributes across video sequences. This is essential for autonomous vehicle perception, robotics, and spatial intelligence systems requiring accurate motion and depth understanding.
Beyond geometric annotation of objects, video AI models increasingly require temporal annotation — labels that describe what is happening across time, not just where objects are in space. This is the fastest-growing segment of video annotation demand, driven by surveillance AI, sports analytics, healthcare procedure analysis, and autonomous system behaviour prediction. HabileData provides three levels of temporal annotation:

Annotating pre-recorded and live video stream of vehicles provided training data for machine learning models for a California based data analytics company helped managing traffic efficiently.
Read full Case Study »
Our annotators assign and maintain unique object track IDs across the full video sequence, including through occlusion events, re-entry after screen exit, and class-changing objects (e.g., a person entering a vehicle). Track ID consistency is the single most important quality factor for object tracking model training and the most frequently failed quality dimension in crowdsourced annotation.
Semantic segmentation in video requires consistent class labels for the same pixel regions across frames as scene elements move, appear, and disappear. Our temporal consistency QA process measures segmentation mask drift across sliding windows of 5 consecutive frames – catching temporal inconsistencies that single-frame QA misses.
For datasets requiring per-frame annotation (no interpolation), our team annotates every frame independently with cross-frame review to enforce temporal consistency. Suitable for low-frame-rate or high-action datasets where interpolation would introduce labeling errors.
Action recognition annotation requires precise temporal boundaries: the exact start and end frame of each activity, not approximations. Our annotators use frame-stepping tools to identify exact action boundaries and apply consistent temporal labels across annotator assignments.
Annotating video with multiple overlapping objects – crowd scenes, multi-vehicle intersections, sports team tracking – requires annotators to maintain consistent track IDs for every object simultaneously across frames. Our multi-object tracking annotation protocols include explicit re-identification rules for ambiguous cases.
Frame interpolation pre-labeling reduces annotation time by 50–70% on video datasets with predictable object motion. Annotators correct interpolation errors rather than labeling from scratch, producing faster, more consistent results. All interpolated labels are human-reviewed before QA.
Video Data Intake and Frame Assessment
We review your video dataset for resolution, frame rate, format, quality, and object density before annotation begins. High-occlusion or fast-motion sequences are flagged for specialist annotator assignment.
Annotation Guideline Creation
We create video-specific annotation guidelines covering class taxonomy, boundary rules, track ID assignment protocols, interpolation standards, and temporal segment labeling conventions.
AI-Assisted Pre-Labeling
For datasets with predictable object motion, we apply key-frame annotation with automated interpolation to propagate labels to intermediate frames. Annotators correct interpolation errors.
Three-Stage QA Review
Stage 1: Primary annotation and track ID assignment. Stage 2: Senior QA review against guideline including temporal consistency check. Stage 3: Automated MOTA calculation across the full annotated sequence.
Delivery in Tracking-Compatible Formats
Annotated video datasets delivered in MOT Challenge format, COCO Video, nuScenes, BDD100K, Waymo Open Dataset format, or custom schema.
We work within your existing annotation platform or provision and configure one for you. Our annotators are trained and actively working on the following video annotation platforms.
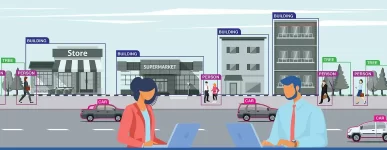
Our video annotation teams have experience and trained ontologies for the following application domains:





Video annotation labels objects, actions, and scenes in video footage to train AI models. Without it, computer vision systems cannot detect, track, or understand the real world. It is the foundation every reliable AI application is built on.
We offer bounding boxes, polygon annotation, semantic segmentation, keypoint annotation, landmark annotation, and 3D cuboid annotation. Each technique is selected based on your model’s specific requirements – not applied generically – so your training data drives real performance gains.
We use domain-trained annotators, multi-tier independent review, and inter-annotator agreement checks on every project. This structured QA pipeline consistently delivers 99%+ accuracy, because your model’s performance depends entirely on the quality of its training data.
Yes. We annotate 50,000+ data points daily through parallel workflows and AI-assisted pre-labeling, with a QA team that scales alongside every project. Frame 500,000 receives the same scrutiny as frame one. Scale is never an excuse for inconsistency.
In-house annotation teams take months to build and divert engineering focus from model development. Outsourcing to HabileData gives you trained specialists and proven QA pipelines immediately with clients reporting up to 60% lower costs and faster time-to-training.
Your data is protected by ISO-certified infrastructure, GDPR-compliant workflows, NDA-signed annotators, encrypted transfers, and role-based access controls. We never use client data to train third-party models. Your footage stays yours, completely and verifiably.
AI pre-labels frames automatically, cutting manual effort by up to 70%. Human specialists then review, correct, and validate every output – catching edge cases automation misses. You get faster delivery and lower cost without the accuracy trade-off that fully automated annotation creates.
Most projects begin within 48 to 72 hours of scope confirmation. New clients can validate our quality through a test batch delivered in 2 to 3 business days – giving you confidence before committing to full-scale production.

Disclaimer: HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@habiledata.com.