
Explore the pivotal role of text annotation in shaping NLP algorithms as we walk you through diverse types of text annotation, annotation tools, case studies, trends, and industry applications. The comprehensive guide throws insights into the Human-in-the-loop approach in text annotation.
Text annotation is a crucial part of natural language processing (NLP), through which textual data is labeled to identify and classify its components. Essential for training NLP models, text annotation involves tasks like named entity recognition, sentiment analysis, and part-of-speech tagging. By providing context and meaning to raw text, it plays a central role in enhancing the performance and accuracy of NLP applications.
Text annotation is not just a technical requirement, but a foundation for the growing NLP market, which witnessed a turnover of over $12 billion in 2020. According to Statista, the market for NLP is projected to grow at a compound annual growth rate (CAGR) of about 25% from 2021 to 2025.
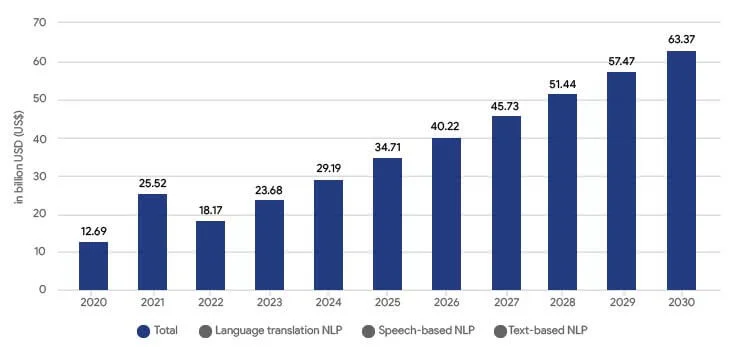
Recent studies have shown that around two-thirds of NLP systems fail after they are put to use. The primary reason for this failure is their inability to deal with the complex data encountered outside of testing environments, highlighting the importance of high-quality text annotation.
Contents
- Challenges in annotating text for NLP projects
- Popular text annotation techniques
- Process of annotating text for NLP
- How does HITL (Human-in-the-loop) approach help?
- How AI companies benefit from text annotation for domain-based AI apps
- Types of text annotation in NLP and their effective use cases
- Text annotation tools
- The future of text annotation
- Conclusion
Challenges in annotating text for NLP projects
Text annotation is a critical step in preparing data for Natural Language Processing (NLP) systems, which rely heavily on accurately labeled datasets. However, it faces many challenges ranging from data volumes and speed to consistency and data security.
- Volume of Data: NLP projects often require large datasets to be effective. Annotators face the daunting task of labeling vast amounts of text, which can be time consuming and mentally taxing. For instance, a project aimed at understanding customer sentiment might need to process millions of product reviews. This sheer volume can lead to fatigue, affecting the quality of the annotation.
- Speed of Production: In our fast-paced digital world, the speed at which text data is produced and needs to be processed is staggering. Social media platforms generate enormous amounts of data daily. Annotators are under pressure to work quickly, which can sometimes compromise the accuracy and depth of annotation. This need for speed can also lead to burnout among annotators.
- Resource Intensiveness: Text annotation is often a time-consuming and labor-intensive process. It requires a significant amount of human effort, which can be costly and inefficient, especially for large datasets.
- Scalability: As the amount of data increases, scaling the annotation process efficiently while maintaining quality is a major challenge. Automated tools can help, but they often require human validation to ensure accuracy.
- Ambiguity in Language: Natural language is inherently ambiguous and context-dependent. Capturing the correct meaning, especially in cases of idiomatic expressions, sarcasm, or context-specific usage, can be difficult. This ambiguity can lead to challenges in ensuring that the annotations accurately reflect the intended meaning.
- Language and Cultural Diversity: Dealing with multiple languages and cultural contexts increases the complexity of annotation. It’s challenging to ensure that annotators understand the nuances of different languages and cultural references.
- Domain-Specific Knowledge: Certain NLP applications require domain-specific knowledge (such as legal, medical, or technical fields). Finding annotators with the right expertise can be difficult and expensive.
- Annotation Guidelines and Standards: Developing clear, comprehensive annotation guidelines is crucial for consistency. These guidelines must be regularly updated and annotators adequately trained, which adds to the complexity and costs.
- Subjectivity in Interpretation: Different annotators may interpret the same text differently. Achieving consensus or a standardized interpretation can be challenging.
- Adaptation to Evolving Language: Language is dynamic and constantly evolving. Keeping the annotation process and guidelines up to date with new slang, terminologies, and language usage patterns is an ongoing challenge.
- Human Bias: Annotators, being human, bring their own perspectives and biases to the task. This can affect how the text is interpreted and labeled. For example, in sentiment analysis, what one annotator might label as a negative sentiment, another might view as neutral. This subjectivity can lead to inconsistencies in the dataset, which in turn can skew the NLP model’s learning and outputs.
- Consistency: Maintaining consistency in annotation across different annotators and over time is a significant challenge. Different interpretations of guidelines, varying levels of understanding, and even changes in annotators’ perceptions over time can lead to inconsistent labeling. Inconsistent annotations can confuse the NLP models, leading to poor performance.
- Data Security: Annotators often work with sensitive data, which might include personal information. Ensuring the security and privacy of this data is paramount. Data breaches can have serious consequences, not just for the individuals whose data is compromised, but also for the organizations handling the data. Annotators and their employers must adhere to strict data protection protocols, adding another layer of complexity to their work.
Get your solutions to text annotation challenges.
Connect with our experts today! »Popular text annotation techniques
In Natural Language Processing (NLP), the method of text annotation plays a pivotal role in shaping the effectiveness of the technology. Understanding the different text annotation techniques is crucial for selecting the most appropriate method for a given project and address the regular challenges generally involved in them. Here are three primary annotation techniques: Manual, Automated, and Semi-Automated Annotation, each with its unique attributes and applications.
| Annotation Technique | Manual Annotation | Automated Annotation | Semi-Automated Annotation |
| Definition and Explanation | Involves human annotators interpreting and labeling text based on specific guidelines. | Uses algorithms and NLP models to automatically label text without human intervention. | Combines manual and automated methods; algorithms make initial annotations, followed by human review and refinement. |
| Pros and Cons | Pros: High accuracy, context understanding, flexibility. Cons: Time-consuming, labor-intensive, potential for human error and bias. | Pros: Fast, efficient, handles large data volumes, cost-effective. Cons: Less accurate for complex texts, dependent on training data quality, struggles with ambiguity. | Pros: Balances speed and accuracy, reduces human workload, adaptable. Cons: Requires both technology and human expertise, intermediate cost, management complexity. |
| Use Cases and Scenarios | Ideal for small datasets, complex texts, academic research, specialized industry applications like healthcare. | Suited for large-scale projects, social media analysis, big data projects where speed is critical. | Perfect for accuracy-important projects with large data volume, corporate feedback analysis, research needing initial fast processing. |
By leveraging these different annotation techniques, organizations and researchers can tailor their approach to suit the specific needs and constraints of their NLP projects, balancing factors like accuracy, speed, and cost-effectiveness.
Confused about what type of text annotation meets your project needs?
Talk to our experts »Process of annotating text for NLP
Text annotation in NLP is a systematic process in which raw text data is methodically labeled to identify specific linguistic elements, such as entities, sentiments, and syntactic structures. This process not only aids in the training of NLP models, but also significantly improves their ability to understand and process natural language. The stages in this process, from data collection to building an effective annotation team, are crucial for ensuring high-quality data annotation and, consequently, superior model performance in NLP applications.
| Stage | Sub-Stage | Details |
| Data Collection and Preparation | Gathering Raw Text Data | Collecting relevant text data from various sources aligning with the project’s objectives. |
| Preprocessing and Cleaning Data | Removing irrelevant content, correcting errors, and standardizing the format for annotation. | |
| Importance of Data Quality | Ensuring high-quality data to avoid inaccurate model training and unreliable results. | |
| Creating Annotation Guidelines | Establishing Clear Guidelines for Annotators | Developing detailed guidelines for consistent and accurate data labeling. |
| Maintaining Consistency in Annotation | Regular guideline reviews and updates to ensure uniformity across different annotators. | |
| Handling Ambiguous Cases and Edge Cases | Providing instructions for dealing with complex or unclear instances in the data. | |
| Building an Annotation Team | Recruiting and Training Annotators | Selecting skilled annotators and providing them with comprehensive training on project specifics. |
| Monitoring and Quality Control | Conducting regular checks and feedback sessions to ensure annotation accuracy. | |
| Ensuring Data Privacy and Security | Implementing measures to protect the confidentiality and integrity of the data. | |
| Annotation Workflow | Step-by-step Annotation Process | Defining data, setting up tools, assigning tasks, and executing annotation. |
| Annotation Interfaces and Workflows | Selecting efficient interfaces and designing effective workflows for annotators. | |
| Incorporating Feedback and Iteration | Utilizing feedback for continuous improvement in the annotation process. |
This comprehensive table encapsulates the entire process of text annotation for NLP, providing a clear roadmap from the initial stages of data collection to the integration of annotated data with machine learning models.
How does HITL (Human-in-the-loop) approach help?
The Human-in-the-Loop (HITL) approach significantly enhances AI-driven data annotation by integrating human expertise into the AI workflow, thereby ensuring greater accuracy and quality. This collaborative technique addresses the limitations of AI, enabling it to navigate complex data more effectively. Key benefits of the HITL approach in text annotation for NLP include:
- Improved Accuracy and Quality: Human experts are better at understanding ambiguous and complex data, allowing them to identify and correct errors that automated systems might overlook. This is particularly beneficial in scenarios involving rare data or languages with limited examples, where machine learning algorithms alone may struggle.
- Enhanced Contextual Understanding: Humans bring nuanced judgment and contextual knowledge to the annotation process, crucial for tasks requiring subjective interpretations, such as sentiment analysis. This human involvement ensures more precise and meaningful labeling of data.
- Edge Case Resolution: HITL is valuable in addressing challenging edge cases that require human judgment and reasoning, which are often difficult for AI to handle accurately. Human annotators can ensure that these rare or complex instances are correctly labeled, enhancing the reliability and performance of the AI models trained on this data.
- Continuous Improvement: The HITL approach facilitates an iterative feedback loop, where human annotators provide insights and feedback to improve automated systems. This collaboration leads to ongoing refinements in the accuracy and quality of annotations over time.
- Active Learning and Querying: HITL systems can use active learning techniques, where the model queries humans for annotations on uncertain or challenging examples, thereby focusing human effort on the most informative instances. This optimizes the annotation process and improves annotation accuracy while reducing overall effort.
- Quality Control: Human annotators adhere to specific quality control measures and guidelines, ensuring that annotations meet the desired standards. Techniques like involving a third-party annotator for consensus or employing consensus-building strategies among multiple annotators enhance the reliability and reduce the impact of individual biases.
HabileData leverages the HITL approach in text annotation and combines the strengths of human intelligence and AI capabilities, resulting in more reliable, accurate, and contextually nuanced NLP models. This synergy is pivotal in advancing the effectiveness of AI-driven data annotation, particularly in complex, ambiguous, or highly subjective annotation tasks.
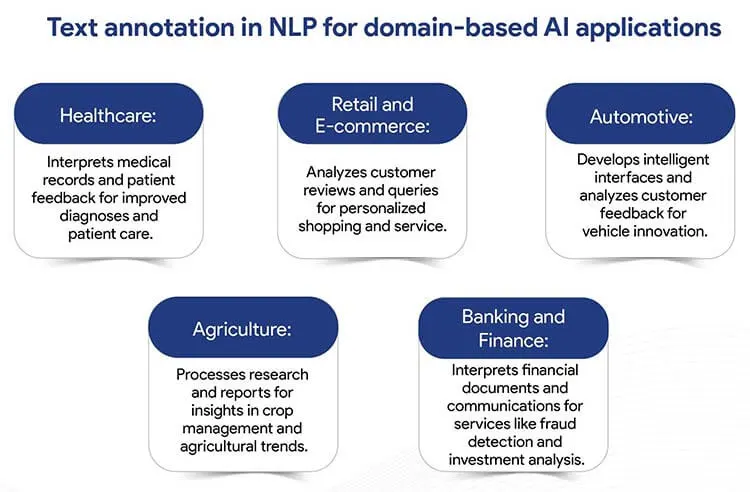
How AI companies benefit from text annotation for domain-based AI apps
Text annotation in NLP is essential for training AI to understand and process language in various industries, enhancing domain-specific applications:
Types of text annotation in NLP and their effective use cases
Text annotation involves categorizing and labeling text data, which is crucial for training NLP models. Each type of annotation serves a specific purpose and finds unique applications in various industries.
Entity Annotation: This involves identifying and labeling specific entities in the text, such as names of people, organizations, locations, and more.
Use cases in NLP
- In healthcare, it’s used to extract key patient information from clinical documents, aiding in patient care and research.
- In legal contexts, it helps in identifying and organizing pertinent details like names, dates, and legal terms from vast documents.
- Useful for extracting company names and financial terms from business reports for market analysis.
Entity Linking: This process connects entities in the text to a larger knowledge base or other entities.
Use cases in NLP
- In journalism, it enriches articles by linking people, places, and events to related information or historical databases.
- In financial analysis, it can link company names to their stock profiles or corporate histories.
Text Classification: This involves categorizing text into predefined groups or classes.
Use cases in NLP
- In customer support, it’s used to sort customer inquiries into categories like complaints, queries, or requests, streamlining the response process.
- In content management, it helps in organizing and classifying articles, blogs, and other written content by topics or themes.
Sentiment Annotation: This type of annotation identifies and categorizes the sentiment expressed in a text segment as positive, negative, or neutral.
Use cases in NLP
- In market research, it’s widely used to analyze customer feedback on products or services.
- In social media monitoring, it helps in gauging public sentiment towards events, brands, or personalities.
- In ecommerce, it is used to evaluate customer feedback to assess product satisfaction levels.
Linguistic Annotation: This adds information about the linguistic properties of the text, such as syntax (sentence structure) and semantics (meaning).
Use cases in NLP
- In language learning applications, it provides detailed grammatical analysis to aid language comprehension.
- For text-to-speech systems, it helps in understanding the context for accurate pronunciation and intonation.
Part-of-Speech (POS) Tagging: This involves labeling each word with its corresponding part of speech, such as noun, verb, adjective, etc.
Use cases in NLP
- In search engines, it assists in parsing queries to deliver more relevant results.
- In content creation, it aids in keyword optimization for SEO purposes.
- In transcription, it is used to enhance voice recognition systems by tagging words in speech transcripts for more accurate context understanding.
Document Classification: Similar to text classification, but on a broader scale, it categorizes entire documents.
Use cases in NLP
- In legal tech, it assists in sorting various legal documents into categories such as ‘contracts’, ‘briefs’, or ‘judgments’ for easier retrieval and analysis.
- In academic research, it aids in organizing scholarly articles and papers by fields and topics.
Coreference Resolution: This identifies when different words or phrases refer to the same entity in a text.
Use cases in NLP
- In news aggregation, it’s crucial for linking different mentions of the same person, place, or event across multiple articles.
- In literature analysis, it helps in tracking characters and themes throughout a narrative.
These examples showcase how text annotation empowers various NLP applications, enhancing their functionality and utility across different domains.
How HabileData nailed text annotation for a German construction company
A Germany-based construction technology company sought to enhance its in-house construction leads data platform for sharing comprehensive construction project data across USA and Europe. Their clientele ranged from small businesses to Fortune 500 companies in the real estate and construction sectors. The company used automated crawlers to gather real-time data on construction projects, which was auto-classified into segments like property type, project dates, location, size, cost, and phases.
However, for accuracy and to append missing information, they partnered with HabileData to verify, validate, and manually annotate 20% of the data that couldn’t be auto-classified.
The project involved comprehending and extracting relevant information from articles, tagging this information based on categories like project size and location, and managing large volumes of articles within a tight 24-hour timeline.
The HabileData team conducted an in-depth assessment of the client’s needs, received domain-specific training, and carried out a rigorous two-step quality check on the classified data. Over 10,000 construction-related articles were processed with effective text annotation techniques, significantly improving the accuracy of the AI algorithms used by the company. This collaboration led to enhanced AI model performance, a 50% cost reduction on the project, and a superior customer experience.
Text annotation tools
Other than understanding the HITL approach, it is crucial to also understand the tools and software that facilitate this process. Text annotation tools are specialized software designed to streamline the labeling of textual data for NLP applications.

Text annotation tools provide an interface for annotators to label data efficiently. These tools often support various annotation types, such as entity recognition, sentiment analysis, and part-of-speech tagging. They range from simple, user-friendly platforms to more advanced systems that offer automation and integration capabilities.
Popular text annotation tools
- Prodigy: A highly interactive and user-friendly tool, Prodigy allows for efficient manual annotation. It supports active learning and is particularly useful in iterative annotation processes.
- Labelbox: This tool is known for its ability to handle large datasets. Labelbox offers a combination of manual and semi-automated annotation features, making it suitable for projects of varying complexity.
- spaCy: spaCy is not just a text annotation tool, but a full-fledged NLP library. It provides functionalities for both annotation and building NLP models, suitable for projects requiring the integration of annotation and model training.
Choosing the right text annotation tool
Selecting an appropriate text annotation tool depends on several factors:
- Project Size and Complexity: For large-scale projects, tools like Labelbox that handle high volumes efficiently are preferable. For more complex annotation tasks, Prodigy with its active learning capabilities, may be more suitable.
- Annotation Type: Different tools excel in different types of annotations. It’s important to choose a tool that aligns well with the specific annotation needs of your project.
- Integration Needs: If integration with other NLP tools or model training is a requirement, spaCy could be an ideal choice.
- Budget and Resource Availability: Some tools are more cost-effective than others and require varying levels of expertise to operate effectively.
The choice of text annotation tools plays a critical role in the efficiency and effectiveness of the text annotation process in NLP projects. The selection should be tailored to the specific needs of the project, considering factors like project scope, annotation requirements, and available resources.
The future of text annotation
Recent advancements in NLP have introduced important trends, such as transfer learning, where a model trained for one task is repurposed for a related task, thus requiring less labeled data. The introduction of machine learning models like GPT and advancements in BERT and ELMo models have revolutionized the understanding of word context in NLP. Additionally, the emergence of low-code/no-code tools has democratized NLP, enabling non-technical users to perform tasks previously limited to data scientists.
As we look toward the future of text annotation in NLP, several key developments are poised to shape this evolving field:
- Advancements in AI-Powered Annotation Tools: Future annotation tools are expected to be more sophisticated, leveraging AI to a greater extent. This could include enhanced automation capabilities, better context understanding, and more efficient handling of large datasets.
- Enhanced Guidelines and Standards: There will probably be a push toward more standardized and universally accepted annotation guidelines, which will help in improving the consistency and quality of annotated data across different projects and domains.
- The Role of Synthetic Data in Annotation: Synthetic data generation is an emerging area that could revolutionize text annotation. By creating artificial yet realistic text data, it offers the potential to train NLP models in more diverse scenarios, reducing reliance on labor-intensive manual annotation.
These developments indicate a future in which text annotation becomes more efficient, accurate, and adaptable, significantly impacting the capabilities and applications of NLP technologies.
Conclusion
Text annotation plays a vital role in the field of Natural Language Processing (NLP), acting as the backbone for training and improving NLP models. From the initial stages of data collection and preparation to the detailed processes of annotation workflow, quality control, and integration with machine learning models, each step is crucial for ensuring the effectiveness and accuracy of NLP applications.
The future of text annotation, marked by advancements in AI-powered tools, enhanced guidelines, and the utilization of synthetic data, points toward a more efficient and sophisticated landscape. The key takeaway is that, as NLP continues to evolve, the importance of meticulous and advanced text annotation processes will become increasingly important, shaping the future capabilities of AI in understanding and processing human language.
Experience the power of precision in your text annotation projects.
Connect with our expert annotators today! »


Snehal Joshi heads the business process management vertical at HabileData, the company offering quality data processing services to companies worldwide. He has successfully built, deployed and managed more than 40 data processing management, research and analysis and image intelligence solutions in the last 20 years. Snehal leverages innovation, smart tooling and digitalization across functions and domains to empower organizations to unlock the potential of their business data.


