Building AI models is tough without accurate, high-quality training data. We solve this with end-to-end AI data preparation services from sourcing and annotation to synthetic data generation delivering secure, compliant, and model-ready datasets for NLP, Large Language Model (LLM), computer vision, and machine learning.
Prepare your data for AI success today »
Inconsistent or unstructured training data reduces AI performance. At HabileData, we deliver domain-specific AI data preparation services includes sourcing, cleansing, enriching, annotating, validating, and generating synthetic data for machine learning, NLP, Generative AI and LLM fine-tuning.
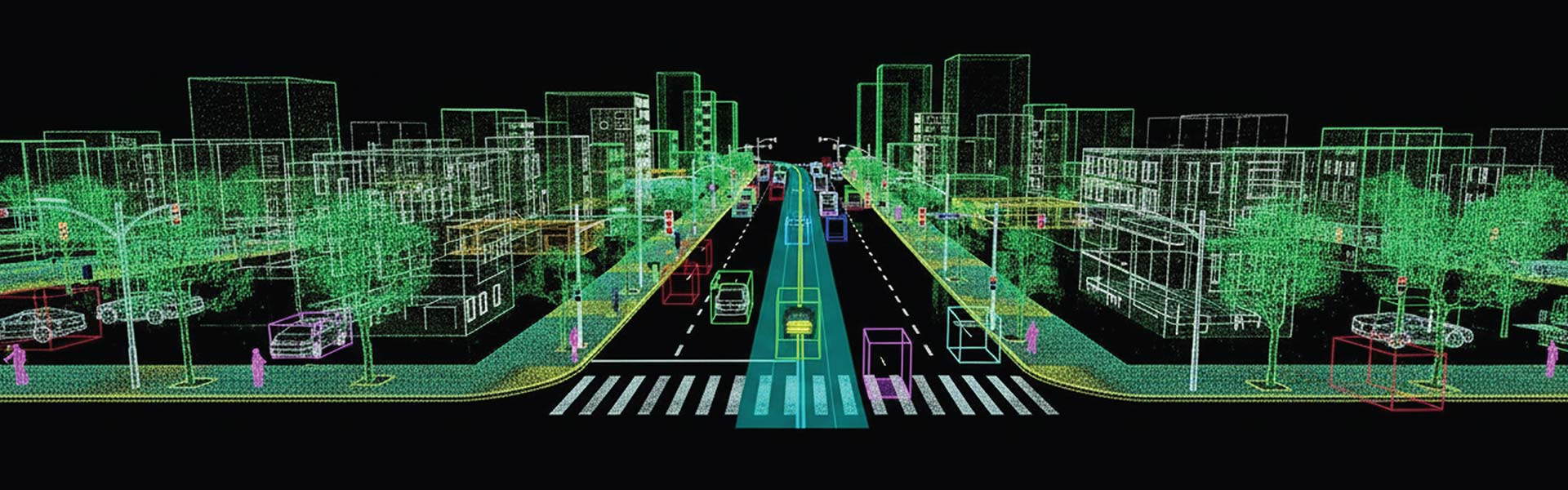
Our QA-led workflows resolve data ambiguity, class imbalance, bias, and scalability challenges across diverse AI projects. Whether you are training multilingual NLP models, autonomous vehicle systems, or healthcare AI, we align each dataset with your model’s logic, labeling conventions, and use case complexity. We specialize in AI dataset creation, AI data preparation, and AI data validation tailored to your industry.
We support edge-case detection, rare scenario simulation, and balanced class representation to improve training coverage. Secure infrastructure, ISO-certified processes, and automated validation tools help us reduce time-to-model, increase data integrity, and accelerate your AI data management outcomes.
Optimize your AI training data sourcing pipeline »

Gather structured and unstructured data from public, licensed, or client sources to support scalable AI training data sourcing across industries.

Clean, normalize, deduplicate, and validate incoming datasets to ensure accuracy, standardization, and readiness for AI data preparation.

Add context and attributes to raw inputs for smarter modeling and better downstream performance in AI dataset creation.

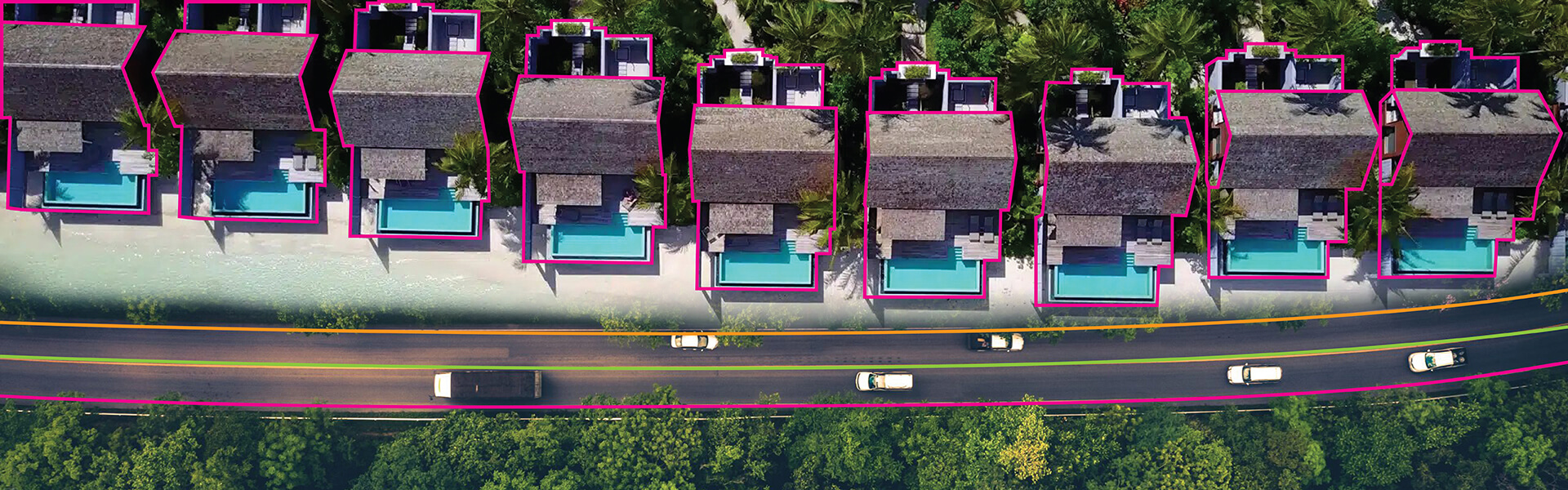
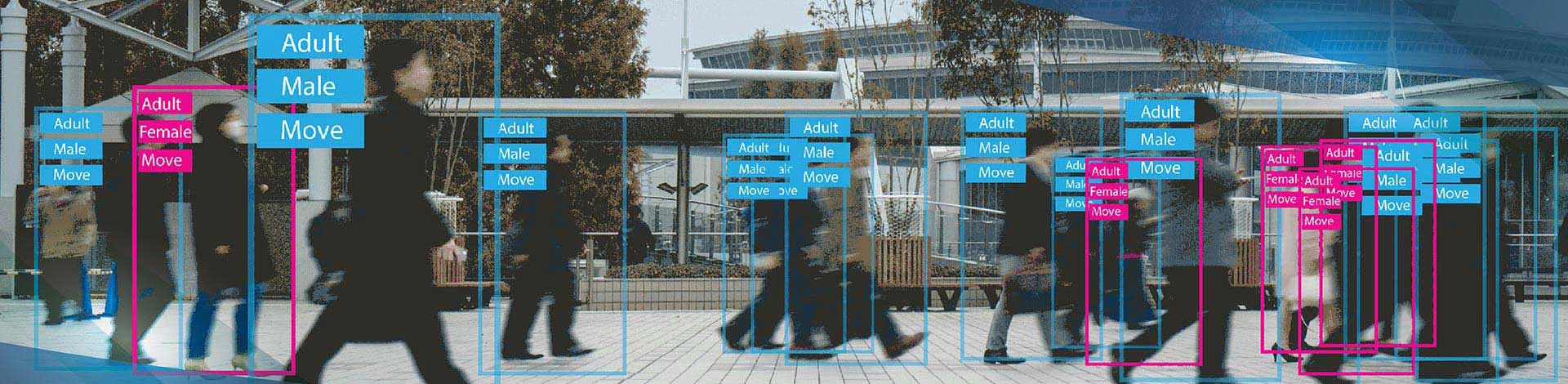
Use domain-specific taxonomies for AI data annotation across text, image, video, and audio to power NLP and computer vision.

Deploy multi-step QA to ensure AI data quality, bias mitigation, and compliance with industry standards.

Create synthetic data using simulation tools and GANs to replicate real-world scenarios and solve data scarcity.

Accelerate data delivery with dedicated experts.

Leverage specialized skills across industries.

Easily manage large, complex data volumes.

Reduce overheads by avoiding in-house setup.

Ensure accuracy through expert QA processes.

Free internal teams to build better models.

Scale teams and tools as the project demands.
AI Data Services Tailored for Industry-Specific Needs.








We curate and source a wide range of data types, including structured, semi-structured, and unstructured data. This includes text, images, video, audio, tabular datasets, and sensor data, depending on the AI model’s needs. Our expertise spans domains such as computer vision, natural language processing (NLP), and machine learning (ML), enabling us to deliver domain-specific datasets tailored to healthcare, e-commerce, automotive, finance, and more. We ensure each dataset is relevant, diverse, and aligned with your training goals to help models learn effectively and perform accurately in real-world scenarios.
We follow a multi-tiered quality assurance process that includes data validation, annotation reviews, expert audits, and automated checks. Our team uses strict guidelines and domain-specific taxonomies to minimize labeling errors and maintain consistency. We also apply statistical sampling, inter-annotator agreement, and QA loops to identify and correct inaccuracies. All processes are documented, monitored, and continually optimized. This ensures your training data is accurate, balanced, and free from bias—leading to more reliable and high-performing AI models.
We use a combination of proprietary data collection, licensed third-party sources, public datasets, and client-provided data—depending on the project scope. Our sourcing strategy ensures data relevance, diversity, and compliance with legal and ethical standards. For custom needs, we can design data collection workflows to gather real-world data through web scraping (where legally permitted), sensor input, surveys, or user interaction. All sources are evaluated for quality, reliability, and suitability to train ML, NLP, and computer vision models effectively.
Yes, absolutely. We tailor every dataset based on your AI model’s architecture, target use case, and performance goals. This includes selecting specific data formats, categories, labeling guidelines, domain coverage, and class distributions. Whether your model needs rare edge cases, multilingual datasets, sentiment nuances, or precise object boundaries, we curate, enrich, and annotate data accordingly. Our consultative approach ensures alignment between data characteristics and model requirements, helping improve training efficiency, accuracy, and generalizability.
Data privacy and security are central to our operations. We follow industry-standard protocols, including encryption, role-based access, anonymization, and secure data transfer channels. Our infrastructure is compliant with data protection regulations like GDPR, CCPA, and others as required. When handling sensitive or client-owned data, we execute NDAs and provide secure environments for processing. We also ensure all personnel are trained in data handling best practices. Our goal is to deliver trustworthy AI training data without compromising your compliance or data integrity.
Yes, we offer synthetic data generation services for a variety of AI use cases. Using advanced techniques such as generative adversarial networks (GANs), 3D rendering, and simulation engines, we create realistic, labeled datasets that reflect diverse scenarios—even those that are hard or costly to capture in real life. Synthetic data helps address data scarcity, protect privacy, and improve model robustness. It is particularly useful for training computer vision and autonomous systems, as well as testing edge cases or rare events.
Turnaround time depends on the project’s complexity, data volume, and the type of processing involved. For standard projects, delivery can range from a few days to a couple of weeks. Larger or more complex datasets—requiring custom annotation, multi-stage QA, or synthetic generation—may take longer. We assess the scope upfront and provide a clear delivery timeline with milestones. Our scalable infrastructure and global workforce allow us to meet tight deadlines without compromising on quality or compliance.
High-quality training data is the foundation of a successful AI project. It directly impacts model accuracy, generalization, and performance. Clean, well-annotated, and diverse datasets enable models to learn meaningful patterns, reduce bias, and handle edge cases effectively. This leads to more reliable predictions, better user experience, and faster deployment. Additionally, quality data reduces the need for retraining and debugging, saving both time and cost. In short, the better the data, the better the AI—making high-quality training data a critical asset in your development pipeline.





Disclaimer: HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@habiledata.com.